Langchain is a powerful programming language that allows developers to efficiently build and customize prompt engineering models in Python. Whether you are a beginner looking to explore the world of prompt engineering or an advanced programmer seeking to take your skills to the next level, Langchain offers a seamless transition from zero to advanced prompt engineering. With its user-friendly syntax and extensive library of built-in functions, Langchain empowers developers to create dynamic and sophisticated prompt engineering models that can enhance natural language processing tasks. In this article, we will delve into the various features and capabilities of Langchain, as well as provide step-by-step guidance on how to harness its full potential in Python.
- Analogical & Step-Back Prompting: A Dive into Recent Advancements by Google DeepMind
- Exploring OpenAI’s ChatGPT Code Interpreter: A Deep Dive into its Capabilities
- 10 Best ChatGPT Prompts for Developing Content Strategy
- 20 Best ChatGPT Prompts for Social Media (November 2023)
- A Closer Look at OpenAI’s DALL-E 3
An important aspect of Large Language Models (LLMs) is the number of parameters these models use for learning. The more parameters a model has, the better it can comprehend the relationship between words and phrases. This means that models with billions of parameters have the capacity to generate various creative text formats and answer open-ended and challenging questions in an informative way.
You are viewing: Zero to Advanced Prompt Engineering with Langchain in Python
LLMs such as ChatGPT, which utilize the Transformer model, are proficient in understanding and generating human language, making them useful for applications that require natural language understanding. However, they are not without their limitations, which include outdated knowledge, inability to interact with external systems, lack of context understanding, and sometimes generating plausible-sounding but incorrect or nonsensical responses, among others.
Addressing these limitations requires integrating LLMs with external data sources and capabilities, which can present complexities and demand extensive coding and data handling skills. This, coupled with the challenges of understanding AI concepts and complex algorithms, contributes to the learning curve associated with developing applications using LLMs.
Nevertheless, the integration of LLMs with other tools to form LLM-powered applications could redefine our digital landscape. The potential of such applications is vast, including improving efficiency and productivity, simplifying tasks, enhancing decision-making, and providing personalized experiences.
In this article, we will delve deeper into these issues, exploring the advanced techniques of prompt engineering with Langchain, offering clear explanations, practical examples, and step-by-step instructions on how to implement them.
Langchain, a state-of-the-art library, brings convenience and flexibility to designing, implementing, and tuning prompts. As we unpack the principles and practices of prompt engineering, you will learn how to utilize Langchain’s powerful features to leverage the strengths of SOTA Generative AI models like GPT-4.
Understanding Prompts
Before diving into the technicalities of prompt engineering, it is essential to grasp the concept of prompts and their significance.
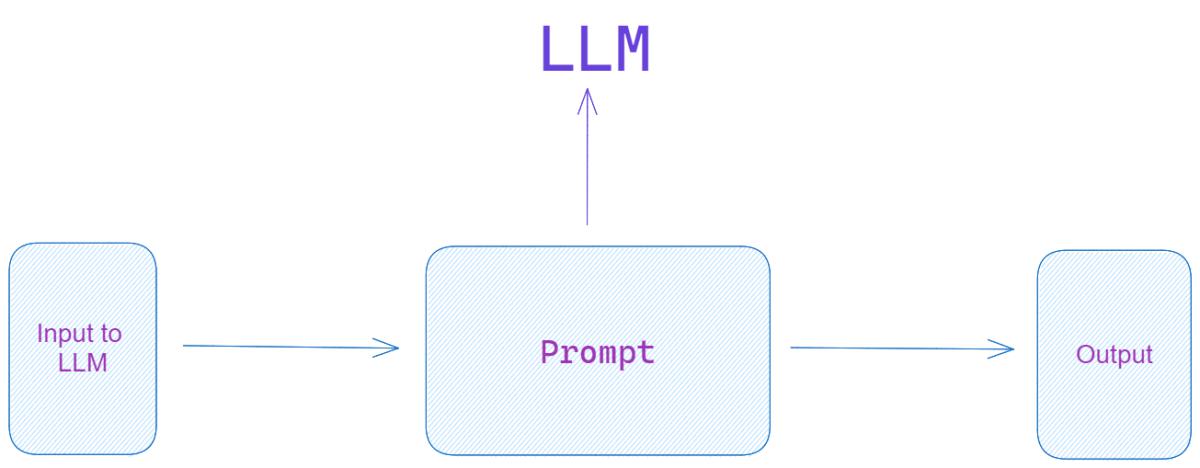
A ‘prompt‘ is a sequence of tokens that are used as input to a language model, instructing it to generate a particular type of response. Prompts play a crucial role in steering the behavior of a model. They can impact the quality of the generated text, and when crafted correctly, can help the model provide insightful, accurate, and context-specific results.
Prompt engineering is the art and science of designing effective prompts. The goal is to elicit the desired output from a language model. By carefully selecting and structuring prompts, one can guide the model toward generating more accurate and relevant responses. In practice, this involves fine-tuning the input phrases to cater to the model’s training and structural biases.
The sophistication of prompt engineering ranges from simple techniques, such as feeding the model with relevant keywords, to more advanced methods involving the design of complex, structured prompts that use the internal mechanics of the model to its advantage.
Langchain: The Fastest Growing Prompt Tool
LangChain, launched in October 2022 by Harrison Chase, has become one of the most highly rated open-source frameworks on GitHub in 2023. It offers a simplified and standardized interface for incorporating Large Language Models (LLMs) into applications. It also provides a feature-rich interface for prompt engineering, allowing developers to experiment with different strategies and evaluate their results. By utilizing Langchain, you can perform prompt engineering tasks more effectively and intuitively.
LangFlow serves as a user interface for orchestrating LangChain components into an executable flowchart, enabling quick prototyping and experimentation.

LangChain fills a crucial gap in AI development for the masses. It enables an array of NLP applications such as virtual assistants, content generators, question-answering systems, and more, to solve a range of real-world problems.
Rather than being a standalone model or provider, LangChain simplifies the interaction with diverse models, extending the capabilities of LLM applications beyond the constraints of a simple API call.
The Architecture of LangChain

LangChain’s main components include Model I/O, Prompt Templates, Memory, Agents, and Chains.
Model I/O
LangChain facilitates a seamless connection with various language models by wrapping them with a standardized interface known as Model I/O. This facilitates an effortless model switch for optimization or better performance. LangChain supports various language model providers, including OpenAI, HuggingFace, Azure, Fireworks, and more.
Prompt Templates
These are used to manage and optimize interactions with LLMs by providing concise instructions or examples. Optimizing prompts enhances model performance, and their flexibility contributes significantly to the input process.
A simple example of a prompt template:
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(input_variables=["subject"],
template="What are the recent advancements in the field of {subject}?")
print(prompt.format(subject="Natural Language Processing"))
As we advance in complexity, we encounter more sophisticated patterns in LangChain, such as the Reason and Act (ReAct) pattern. ReAct is a vital pattern for action execution where the agent assigns a task to an appropriate tool, customizes the input for it, and parses its output to accomplish the task. The Python example below showcases a ReAct pattern. It demonstrates how a prompt is structured in LangChain, using a series of thoughts and actions to reason through a problem and produce a final answer:
PREFIX = """Answer the following question using the given tools:"""
FORMAT_INSTRUCTIONS = """Follow this format:
Question: {input_question}
Thought: your initial thought on the question
Action: your chosen action from [{tool_names}]
Action Input: your input for the action
Observation: the action's outcome"""
SUFFIX = """Start!
Question: {input}
Thought:{agent_scratchpad}"""
Memory
See more : Analogical & Step-Back Prompting: A Dive into Recent Advancements by Google DeepMind
Memory is a critical concept in LangChain, enabling LLMs and tools to retain information over time. This stateful behavior improves the performance of LangChain applications by storing previous responses, user interactions, the state of the environment, and the agent’s goals. The ConversationBufferMemory and ConversationBufferWindowMemory strategies help keep track of the full or recent parts of a conversation, respectively. For a more sophisticated approach, the ConversationKGMemory strategy allows encoding the conversation as a knowledge graph which can be fed back into prompts or used to predict responses without calling the LLM.
Agents
An agent interacts with the world by performing actions and tasks. In LangChain, agents combine tools and chains for task execution. It can establish a connection to the outside world for information retrieval to augment LLM knowledge, thus overcoming their inherent limitations. They can decide to pass calculations to a calculator or Python interpreter depending on the situation.
Agents are equipped with subcomponents:
- Tools: These are functional components.
- Toolkits: Collections of tools.
- Agent Executors: This is the execution mechanism that allows choosing between tools.
Agents in LangChain also follow the Zero-shot ReAct pattern, where the decision is based only on the tool’s description. This mechanism can be extended with memory in order to take into account the full conversation history. With ReAct, instead of asking an LLM to autocomplete your text, you can prompt it to respond in a thought/act/observation loop.
Chains
Chains, as the term suggests, are sequences of operations that allow the LangChain library to process language model inputs and outputs seamlessly. These integral components of LangChain are fundamentally made up of links, which can be other chains, or primitives such as prompts, language models, or utilities.
Imagine a chain as a conveyor belt in a factory. Each step on this belt represents a certain operation, which could be invoking a language model, applying a Python function to a text, or even prompting the model in a particular way.
LangChain categorizes its chains into three types: Utility chains, Generic chains, and Combine Documents chains. We’ll dive into Utility and Generic chains for our discussion.
- Utility Chains are specifically designed to extract precise answers from language models for narrowly defined tasks. For example, let’s take a look at the LLMMathChain. This utility chain enables language models to perform mathematical calculations. It accepts a question in natural language, and the language model in turn generates a Python code snippet which is then executed to produce the answer.
- Generic Chains, on the other hand, serve as building blocks for other chains but cannot be directly used standalone. These chains, such as the LLMChain, are foundational and are often combined with other chains to accomplish intricate tasks. For instance, the LLMChain is frequently used to query a language model object by formatting the input based on a provided prompt template and then passing it to the language model.
Step-by-step Implementation of Prompt Engineering with Langchain
We will walk you through the process of implementing prompt engineering using Langchain. Before proceeding, ensure that you have installed the necessary software and packages.
You can take advantage of popular tools like Docker, Conda, Pip, and Poetry for setting up LangChain. The relevant installation files for each of these methods can be found within the LangChain repository at This includes a Dockerfile for Docker, a requirements.txt for Pip, a pyproject.toml for Poetry, and a langchain_ai.yml file for Conda.
In our article we will use Pip, the standard package manager for Python, to facilitate the installation and management of third-party libraries. If it’s not included in your Python distribution, you can install Pip by following the instructions at https://pip.pypa.io/.
To install a library with Pip, use the command pip install library_name.
However, Pip doesn’t manage environments on its own. To handle different environments, we use the tool virtualenv.
In the next section, we will be discussing model integrations.
Step 1: Setting up Langchain
First, you need to install the Langchain package. We are using Windows OS. Run the following command in your terminal to install it:
pip install langchain
Step 2: Importing Langchain and other necessary modules
Next, import Langchain along with other necessary modules. Here, we also import the transformers library, which is extensively used in NLP tasks.
import langchain from transformers import AutoModelWithLMHead, AutoTokenizer
Step 3: Load Pretrained Model
Open AI
OpenAI models can be conveniently interfaced with the LangChain library or the OpenAI Python client library. Notably, OpenAI furnishes an Embedding class for text embedding models. Two key LLM models are GPT-3.5 and GPT-4, differing mainly in token length. Pricing for each model can be found on OpenAI’s website. While there are more sophisticated models like GPT-4-32K that have higher token acceptance, their availability via API is not always guaranteed.

Accessing these models requires an OpenAI API key. This can be done by creating an account on OpenAI’s platform, setting up billing information, and generating a new secret key.
import os os.environ["OPENAI_API_KEY"] = 'your-openai-token'
After successfully creating the key, you can set it as an environment variable (OPENAI_API_KEY) or pass it as a parameter during class instantiation for OpenAI calls.
Consider a LangChain script to showcase the interaction with the OpenAI models:
from langchain.llms import OpenAI llm = OpenAI(model_name="text-davinci-003") # The LLM takes a prompt as an input and outputs a completion prompt = "who is the president of the United States of America?" completion = llm(prompt)
The current President of the United States of America is Joe Biden.
In this example, an agent is initialized to perform calculations. The agent takes an input, a simple addition task, processes it using the provided OpenAI model and returns the result.
Hugging Face
Hugging Face is a FREE-TO-USE Transformers Python library, compatible with PyTorch, TensorFlow, and JAX, and includes implementations of models like BERT, T5, etc.
Hugging Face also offers the Hugging Face Hub, a platform for hosting code repositories, machine learning models, datasets, and web applications.
To use Hugging Face as a provider for your models, you’ll need an account and API keys, which can be obtained from their website. The token can be made available in your environment as HUGGINGFACEHUB_API_TOKEN.
Consider the following Python snippet that utilizes an open-source model developed by Google, the Flan-T5-XXL model:
from langchain.llms import HuggingFaceHub
llm = HuggingFaceHub(model_kwargs={"temperature": 0.5, "max_length": 64},repo_)
prompt = "In which country is Tokyo?"
completion = llm(prompt)
print(completion)
See more : A Closer Look at OpenAI’s DALL-E 3
This script takes a question as input and returns an answer, showcasing the knowledge and prediction capabilities of the model.
Step 4: Basic Prompt Engineering
To start with, we will generate a simple prompt and see how the model responds.
prompt="Translate the following English text to French: "{0}""
input_text="Hello, how are you?"
input_ids = tokenizer.encode(prompt.format(input_text), return_tensors="pt")
generated_ids = model.generate(input_ids, max_length=100, temperature=0.9)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
In the above code snippet, we provide a prompt to translate English text into French. The language model then tries to translate the given text based on the prompt.
Step 5: Advanced Prompt Engineering
While the above approach works fine, it does not take full advantage of the power of prompt engineering. Let’s improve upon it by introducing some more complex prompt structures.
prompt="As a highly proficient French translator, translate the following English text to French: "{0}""
input_text="Hello, how are you?"
input_ids = tokenizer.encode(prompt.format(input_text), return_tensors="pt")
generated_ids = model.generate(input_ids, max_length=100, temperature=0.9)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
In this code snippet, we modify the prompt to suggest that the translation is being done by a ‘highly proficient French translator. The change in the prompt can lead to improved translations, as the model now assumes a persona of an expert.
Building an Academic Literature Q&A System with Langchain
We’ll build an Academic Literature Question and Answer system using LangChain that can answer questions about recently published academic papers.

Firstly, to set up our environment, we install the necessary dependencies.
pip install langchain arxiv openai transformers faiss-cpu
Following the installation, we create a new Python notebook and import the necessary libraries:
from langchain.llms import OpenAI from langchain.chains.qa_with_sources import load_qa_with_sources_chain from langchain.docstore.document import Document import arxiv
The core of our Q&A system is the ability to fetch relevant academic papers related to a certain field, here we consider Natural Language Processing (NLP), using the arXiv academic database. To perform this, we define a function get_arxiv_data(max_results=10). This function collects the most recent NLP paper summaries from arXiv and encapsulates them into LangChain Document objects, using the summary as content and the unique entry id as the source.
We’ll use the arXiv API to fetch recent papers related to NLP:
def get_arxiv_data(max_results=10):
search = arxiv.Search(
query="NLP",
max_results=max_results,
sort_by=arxiv.SortCriterion.SubmittedDate,
)
documents = []
for result in search.results():
documents.append(Document(
page_content=result.summary,
metadata={"source": result.entry_id},
))
return documents
This function retrieves the summaries of the most recent NLP papers from arXiv and converts them into LangChain Document objects. We’re using the paper’s summary and its unique entry id (URL to the paper) as the content and source, respectively.
def print_answer(question):
print(
chain(
{
"input_documents": sources,
"question": question,
},
return_only_outputs=True,
)["output_text"]
)
Let’s define our corpus and set up LangChain:
sources = get_arxiv_data(2) chain = load_qa_with_sources_chain(OpenAI(temperature=0))
With our academic Q&A system now ready, we can test it by asking a question:
print_answer("What are the recent advancements in NLP?")
The output will be the answer to your question, citing the sources from which the information was extracted. For instance:
Recent advancements in NLP include Retriever-augmented instruction-following models and a novel computational framework for solving alternating current optimal power flow (ACOPF) problems using graphics processing units (GPUs). SOURCES:
You can easily switch models or alter the system as per your needs. For example, here we’re changing to GPT-4 which end up giving us a much better and detailed response.
sources = get_arxiv_data(2) chain = load_qa_with_sources_chain(OpenAI(model_name="gpt-4",temperature=0))
Recent advancements in Natural Language Processing (NLP) include the development of retriever-augmented instruction-following models for information-seeking tasks such as question answering (QA). These models can be adapted to various information domains and tasks without additional fine-tuning. However, they often struggle to stick to the provided knowledge and may hallucinate in their responses. Another advancement is the introduction of a computational framework for solving alternating current optimal power flow (ACOPF) problems using graphics processing units (GPUs). This approach utilizes a single-instruction, multiple-data (SIMD) abstraction of nonlinear programs (NLP) and employs a condensed-space interior-point method (IPM) with an inequality relaxation strategy. This strategy allows for the factorization of the KKT matrix without numerical pivoting, which has previously hampered the parallelization of the IPM algorithm. SOURCES:
A token in GPT-4 can be as short as one character or as long as one word. For instance, GPT-4-32K, can process up to 32,000 tokens in a single run while GPT-4-8K and GPT-3.5-turbo support 8,000 and 4,000 tokens respectively. However, it’s important to note that every interaction with these models comes with a cost that is directly proportional to the number of tokens processed, be it input or output.
In the context of our Q&A system, if a piece of academic literature exceeds the maximum token limit, the system will fail to process it in its entirety, thus affecting the quality and completeness of responses. To work around this issue, the text can be broken down into smaller parts that comply with the token limit.
FAISS (Facebook AI Similarity Search) assists in quickly finding the most relevant text chunks related to the user’s query. It creates a vector representation of each text chunk and uses these vectors to identify and retrieve the chunks most similar to the vector representation of a given question.
It’s important to remember that even with the use of tools like FAISS, the necessity to divide the text into smaller chunks due to token limitations can sometimes lead to the loss of context, affecting the quality of answers. Therefore, careful management and optimization of token usage are crucial when working with these large language models.
pip install faiss-cpu langchain CharacterTextSplitter
After making sure the above libraries are installed, run
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.faiss import FAISS
from langchain.text_splitter import CharacterTextSplitter
documents = get_arxiv_data(max_results=10) # We can now use feed more data
document_chunks = []
splitter = CharacterTextSplitter(separator=" ", chunk_size=1024, chunk_overlap=0)
for document in documents:
for chunk in splitter.split_text(document.page_content):
document_chunks.append(Document(page_content=chunk, metadata=document.metadata))
search_index = FAISS.from_documents(document_chunks, OpenAIEmbeddings())
chain = load_qa_with_sources_chain(OpenAI(temperature=0))
def print_answer(question):
print(
chain(
{
"input_documents": search_index.similarity_search(question, k=4),
"question": question,
},
return_only_outputs=True,
)["output_text"]
)
With the code complete, we now have a powerful tool for querying the latest academic literature in the field of NLP.
Recent advancements in NLP include the use of deep neural networks (DNNs) for automatic text analysis and natural language processing (NLP) tasks such as spell checking, language detection, entity extraction, author detection, question answering, and other tasks. SOURCES:
Conclusion
The integration of Large Language Models (LLMs) into applications has accelerate adoption of several domains, including language translation, sentiment analysis, and information retrieval. Prompt engineering is a powerful tool in maximizing the potential of these models, and Langchain is leading the way in simplifying this complex task. Its standardized interface, flexible prompt templates, robust model integration, and the innovative use of agents and chains ensure optimal outcomes for LLMs’ performance.
However, despite these advancements, there are few tips to keep in mind. As you use Langchain, it’s essential to understand that the quality of the output depends heavily on the prompt’s phrasing. Experimenting with different prompt styles and structures can yield improved results. Also, remember that while Langchain supports a variety of language models, each one has its strengths and weaknesses. Choosing the right one for your specific task is crucial. Lastly, it’s important to remember that using these models comes with cost considerations, as token processing directly influences the cost of interactions.
As demonstrated in the step-by-step guide, Langchain can power robust applications, such as the Academic Literature Q&A system. With a growing user community and increasing prominence in the open-source landscape, Langchain promises to be a pivotal tool in harnessing the full potential of LLMs like GPT-4.
That concludes the article: Zero to Advanced Prompt Engineering with Langchain in Python
I hope this article has provided you with valuable knowledge. If you find it useful, feel free to leave a comment and recommend our website!
Click here to read other interesting articles: AI
Source: wubeedu.com
#Advanced #Prompt #Engineering #Langchain #Python
Source: https://wubeedu.com
Category: Prompt Engineering